seeWorld Wide Web consortium site for specifications http://www.w3c.org/ and http://www.w3c.org/XML/
XML is a way of peeling the information in a tree of Element nodes out into a string of characters for transmission and then parsing the string back into a tree. The information sent is the structure of the tree and the content of the tree. At an element Node there may be "CharData? ((element | Reference | CDSect | PI | Comment) CharData?)* ". This is optional text followed by any number of elements, References, Character Data sections, Processing Instructions, Comments, all interspersed with more optional text. See the above World Wide Web consortium site for specifications.
 Imagine
two pieces of string attached to the node ElementTreeRoot in the tree to our
right. As each end of the string is pulled the tree is split down the middle.
Step by step we get
Imagine
two pieces of string attached to the node ElementTreeRoot in the tree to our
right. As each end of the string is pulled the tree is split down the middle.
Step by step we get
|
<ElementTreeRoot>
</ElementTreeRoot> |
Further splitting of the tree of Elements produces
|
<ElementTreeRoot>
</ElementTreeRoot> |
When the tree of Elements is fully pulled apart into a string of characters of Element Nodes we finish up with
<ElementTreeRoot> |
When we add in the content at each node into this string of characters we finish up with
|
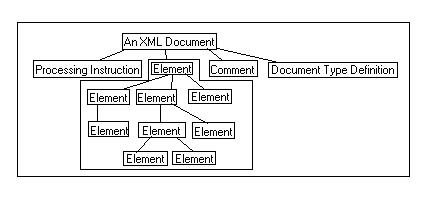
The rules for a Document in XML defines a document as a prolog followed by an element followed by any number of Misc ([1] document ::= prolog element Misc* )
Where a proglog is none or one XML declaration (<?xml version=1?>) followed by any number of Misc and none or one Document type declaration followed by any number of Misc([22] prolog ::= XMLDecl? Misc* (doctypedecl Misc*)? )
Misc is a Comment or a processing Instruction or whitespace such as spaces, line feeds, carriage returns ([27] Misc ::= Comment | PI | S)
[39] element ::= EmptyElemTag | STag content ETag
[43] content ::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
If you are seriously Interested I suggest you read the details at the World Wide WEB Consortium's site http://www.w3c.org/
Best regards - Trevor Croll